

You asked the agent to wire a new step into your workflow, and everything looked fine at first glance: tools ran, steps printed, and the closing message sounded like someone who had just finished real work. Then you opened the diff and noticed the uncomfortable part. The project still builds, the summary still reads like a small release note, but the agent also invented a constant, guessed an API you never documented, or filled a missing detail with something that sounds correct until you actually check it.
That gap between a confident tone and the real content is why I don’t treat agent output the same way I treat a teammate’s pull request.
Recently I joined a company project to build an AI workflow, including the orchestrator layer, and I spent a lot of time with LLM agents and SDKs. The lesson that stuck with me is simple: when agents are wrong, they often don’t stop. They keep going, and if you trust the final message too much, you pay for it later in production.
Agent hallucination
What is agent hallucination?
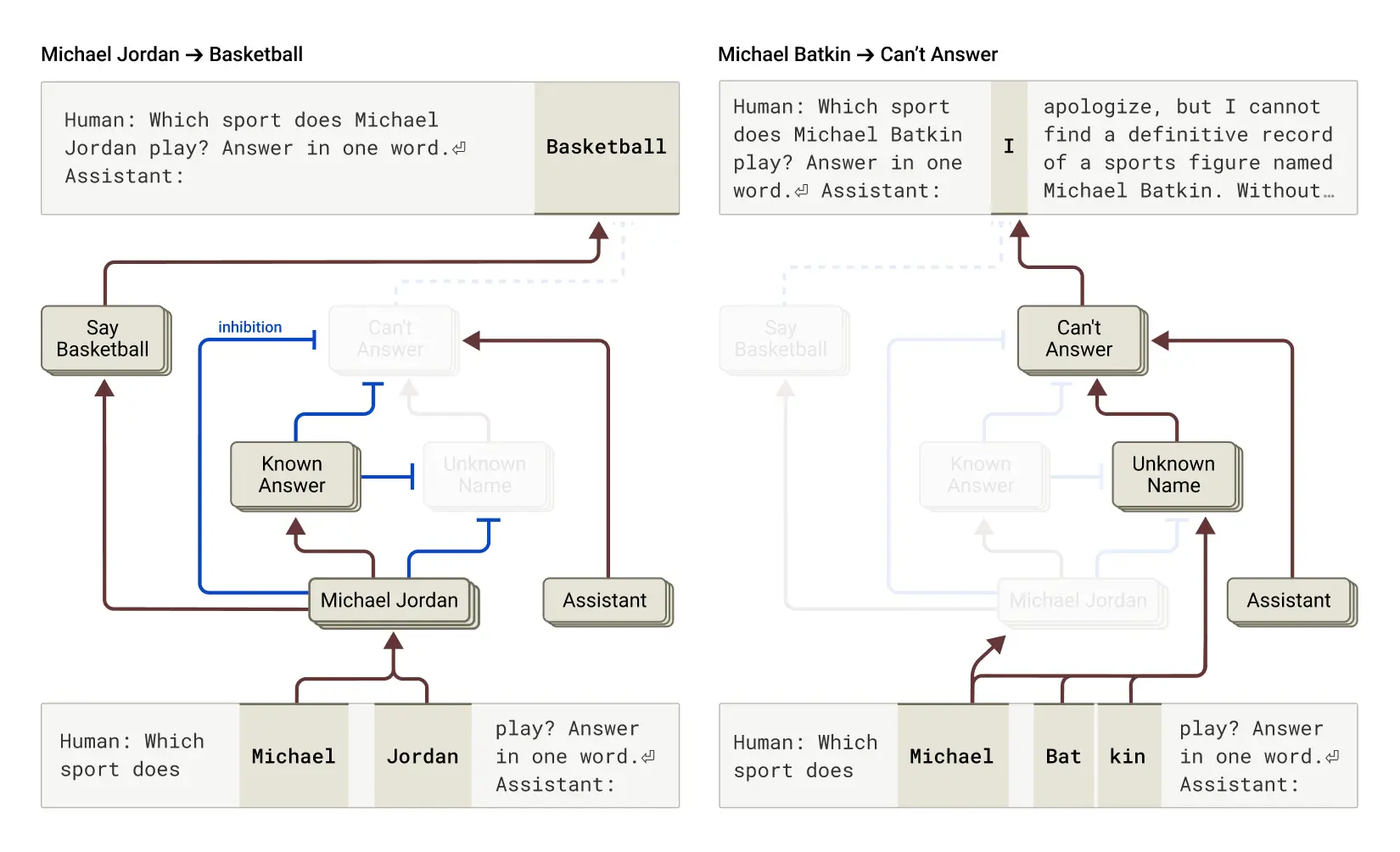
If you ask a person a hard question, you usually see some hesitation. With an agent, you can get a very complete answer instead, with paths, names, and numbers that look real. In our workflow we often saw the agent miss a fact in the context, assume it, and continue as if it had already verified it. The flow still looked “done” and the wording still sounded sure, which is worse than a clear error because you might ship it without a careful second read.
So the scary part is not only wrong text. It is wrong text that still reads like a correct report.
Why agents hallucinate
A few things come together.
Training pushes the model to answer. OpenAI’s article on why language models hallucinate explains that these systems are trained to be helpful and to complete the request. Saying “I don’t know” is natural for humans, but for the model a smooth guess can feel easier than admitting a gap.
The model is trained to finish the reply. It is built to produce a full answer, not to leave holes. When the context is thin, the answer can still sound smooth even when it is not grounded in your sources.
Predicting the next token is not the same as checking facts. The model can look certain because the next words flow well. Anthropic’s research on tracing thoughts in language models is a good reminder that what happens inside the model is not the same as proof in the real world.
This is not about the model being “evil” or lazy. It is how the technology works today: good style and correct facts can still come apart.
Can LLM providers fix it?
They can make it better, but they can’t promise it will never happen. Some questions are impossible to answer from the evidence you have, and the model can still think it knows the answer.
So I don’t wait for a perfect model. I treat a finished answer as something I still need to verify myself.
Protect yourself as an LLM user
Prompt engineering still matters
Prompting won’t fix every case, but it is cheap to try and it helps more than skipping it.
Let the model say it doesn’t know. I add clear instructions: if something is unclear, say you don’t have enough information and ask a human instead of guessing.
Ask for steps before the final answer. When the model writes the reasoning first, bad assumptions often show up earlier.
Ask for proof from the documents. For doc-heavy work, one pattern that worked for us was: after drafting, check each claim, attach a quote from the source, and remove anything you cannot support. Mark the removed spots so the hole is visible.
Claude also collects more ideas in one place: Strengthen guardrails: reduce hallucinations.
Add deterministic rails

Sometimes, I even face the agent skips prompt instructions, so I use prompts as guidance and use code and deterministic process as the real guardrails.
Hooks
Hooks Claude Code hooks let you run commands at fixed points in the flow. The hooks guide shows examples like auto-handling permissions.
For example, I used PreToolUse to stop reads and writes outside allowed paths, block risky commands, and keep changes in the areas we trust.
Gates
A gate means you don’t move to the next step until a script passes. We used completion checkpoints to verify output, and if checks failed we sent the error back to the agent instead of continuing.
For example, I used TaskCompleted as a gate to run xcodebuild command to verify if the code changes can be built.
With the gate check resule, we can apply the concept Ralph Wiggum to loop until the agent pass the gate.
If you don’t use Claude Code, Git hooks are basically the same idea—we have been formatting and validating commits for years, and agents just make the need more visible.
Logging and observability
Hooks and scripts don’t remove the original issue, which is often missing context that makes the model guess. We added monitoring so we could improve over time: for example, a second pass on transcripts to flag suspicious patterns and store reports, prompts that ask the agent to note when it feels unsure, and simple metrics like how often it assumed facts or skipped steps. You don’t need a perfect dashboard on day one; you need a loop where you can see problems and adjust prompts and context.
Conclusion
Agents are useful, but a confident summary is not the same as a correct change. I still use them every day, with clear limits, automatic checks, and the mindset that I own the final result.
If you have patterns that work well for your team, especially around gates and logs, I’d love to hear them in the comments.